一直很想写一篇关于多线程的文章,于是搜了很多文章,自己琢磨了许久才敢下笔 ,那么开始吧。
ThreadPoolExecutor线程池初探
jdk8线程池类ThreadPoolExecutor的完整构造方法如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler); corePoolSize: 核心线程数,会一直存活,即使没有任务,线程池也会维护线程的最少数量。maximumPoolSize: 最大线程数,一个线程池最大的可运行线程数目。keepAliveTime: 线程等待新任务的时间。线程会等待分配新任务的时间,如果超时还没有等到新任务那么线程会退出,直到当前的线程数=corePoolSize。unit: 线程等待新任务的时间单位。workQueue: 线程池用的缓冲队列,常用的是:java.util.concurrent. ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueuePrivilegedThreadFactory: 默认的线程工厂,创建线程用的。defaultHandler: 线程池中的数量大于maximumPoolSize,对拒绝任务的处理策略,默认值ThreadPoolExecutor.AbortPolicy()。线程池运行过程猜想
下面上一段代码测试:
public static void main(String[] args) {
BlockingQueue queue=new LinkedBlockingQueue<>(4);
final ExecutorService threadPool = new ThreadPoolExecutor(2,6,1,TimeUnit.DAYS,queue);
for (int i=1;i<=15;i++) {
final int finalI = i;
threadPool.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + “开始任务” + finalI);
System.out.println();
try {
Thread.sleep(1000 * 60);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + “结束任务” + finalI);
}
});
}
threadPool.shutdown();
System.out.println(“主线程结束了”);
}
测试代码运行结果:
pool-1-thread-1开始任务1
pool-1-thread-2开始任务2
pool-1-thread-3开始任务7
pool-1-thread-4开始任务8
pool-1-thread-5开始任务9
pool-1-thread-6开始任务10
Exception in thread “main” java.util.concurrent.RejectedExecutionException: Task com.houbank.mls.test.ThreadTest$1@7eda2dbb rejected from java.util.concurrent.ThreadPoolExecutor@6576fe71[Running, pool size = 6, active threads = 6, queued tasks = 4, completed tasks = 0]
at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2047)
运行结果总共6个线程在执行任务,线程1执行任务1,线程2执行任务2,线程3执行任务7?,线程4执行任务8?,线程5执行任务9?,线程6执行任务10? 为什么会是这种结果呢? 原来:
首先创建线程池的的时候,核心线程数为2,最大线程数为6,线程等待任务的时间为1 day,同时队列采用LinkedbBlockingQuenel来缓存任务,队列缓存任务的长度是4。
每次执行execute()方法的时候线程池
step1:如果当前运行的线程数小于corePoolSize,会立即创建一个线程运行任务。step2:如果当前运行的线程数大于等于corePoolSize,会把任务缓存到队列中。step3:如果队列放满了,而且此时的当前运行线程数小于maximumPoolSize,还是要创建一个线程来运行任务。step4:如果队列满了,同时前运行线程数等于或大于maximumPoolSize时,拒绝新任务抛出异常。即:任务1和2 execute()时,创建线程执行任务。此时当前运行线程为2,达到了corPoolSize指定核心线程数。任务3,4,5,6 execute()时直接把任务放到缓存队列里,同时缓存队列size=4达到饱和。任务7,8,9,10 execute()时还是要创建线程来执行的,同时当前运行线程数累加到6达到maximumPoolSize饱和。所以余下的任务被拒绝并抛出异常。
jdk8的相关源码
public class ThreadPoolExecutor extends AbstractExecutorService {
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
//step1:如果当前运行线程数小于corePoolSize,addWorker(创建线程并执行任务)
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//step2:如果当前运行线程数大于等于corePoolSize,会把任务加到队列中
//下面是拒绝任务的情况 一般不会进 主要是线程池被急停
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//如果队列满了即step2的offer结果为fasle 往后执行
//step3: 继续创建线程来执行任务,
else if (!addWorker(command, false))
//如果创建失败,那就应该是达到maximumPoolSize饱和了,并采用策略拒绝任务
reject(command);
}
}创建线程启动任务
由上可知 addWoeker()方法是来创建线程启动任务的,那么线程把起始任务执行完毕 又是如何从队列中获取新任务来执行的呢?直接看代码
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// step1:参数检验 运行状态是否为RUNNING 是否有任务 是否有缓存队列
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
//step1:参数检验完再看此时的运行状态 如果不是RUNNING 赶紧跳转到第一行retry从头开始检验
if (runStateOf(c) != rs)
continue retry;
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//step2:核心代码 把任务委托给Worker来创建线程并启动任务
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
//step3:加锁 把创建的的worker加入到set集合里,并设置标识。
//因为这里存在并发,操作的是成员变量,workers是Set,每个子线程共享
try {
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
//step3: 操作完数据后解锁
mainLock.unlock();
}
if (workerAdded) {
//step4: threadFactory新创建的线程包装了Worker对象,在执行新创建线程的run方法时,调用到了Worker对象的run方法
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
以下是内部类Worker的相关方法:
----------每次创建一个worker的时候,都先从工厂里创建一个线程,同时把任务赋给该线程,worker持有该线程。
Worker(Runnable firstTask) {
setState(-1);
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
----------需要注意worker也是实现runnable的 所以也需要实现任务方法 run()
public void run() {
runWorker(this);
}
----------运行任务
final void runWorker(Worker w) {
//step1: 从当前的worker中获得含有任务的线程
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//while循环 ,第一次从worker中获得任务,以后都是getTask()方法来获得任务
while (task != null || (task = getTask()) != null) {
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
//task是获得的任务 执行任务的执行体
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}----------从队列中获得新任务:
<pre><code>private Runnable getTask() {
boolean timedOut = false;
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
//从队列中获取任务 如果有时间限制 那么用poll 没有时间限制 用take
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
最后附上简单的流程图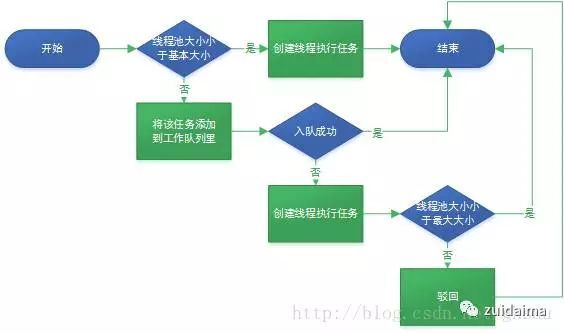
以上就是本人的一点小分析,还有很多遗漏的地方等待后续补进
感谢博客:
https://my.oschina.net/u/1398304/blog/376827
http://shmilyaw-hotmail-com.iteye.com/blog/1897638
ps: 为什么ThreadPoolExecutor的addWorker()方法里调用t.start() 会调用Worker()的run方法
解释:
Worker w = null;
w = new Worker(firstTask);
final Thread t = w.thread;t是Worker类的一个成员变量thread,上面代码意思是传一个初始任务给Worker给Worker,在把Worker创建的线程赋值给t。
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}Worker是ThreadPoolExecutor的内部类,接收到firstTask后调用线程工厂来创建线程,并把自己即this传进去,
getThreadFactory()返回的是ThreadPoolExecutor的成员变量threadFactory,如果自己没有自定义并setThreadFactory的话,默认使用Executors.defaultThreadFactory(),这个在定义线程池就已经赋值了,就不贴代码了。查看Executors内部类defaultThreadFactory的newThread()方法
public Thread newThread(Runnable r) {//Worker也是实现Runnable的
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
可以看出newThread()就是定义了即将要创建线程所在的group,线程要执行的目标任务r,线程的名称name (DefaultThreadFactory构造方法里有赋值namePrefix,有兴趣自看),还有运行的stacksize大小(0就是忽略的意思,最后创建线程还是调用Thread的构造方法。
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc) {……
经过Thread多个构造方法最终进入上面的构造方法,里面定义了线程的安全性,执行等级等,有机会独立开一章。可以看出我们传进的Worker对象最终变成了target,target就是目标任务,线程启动后就得要执行目标任务的run()方法
线程启动需要调用Thread的start(),Thread的start()方法里调用了start0(),
private native void start0();
jvm调用start0的时候会调用Thread的run方法
public void run() {
if (target != null) {
target.run();
}
}
很不幸的是run方法就是启动目标任务的run方法,目标任务就是我们之前传进来的Worker。
ps:idea多线程测试
第一,idea的dubug默认是查看所有线程,多线程调试最好修改idea配置
Ctrl+shift+F8 -> 去掉All 选择Thread 这样就可以进行单条线程测试了。如果有子线程运行并且卡在breakpoint会有弹窗征求你是否切换线程
第二:t.start()方法启动线程,线程全部进入Runnable状态等待cpu分配时间碎片,如果系统是单核,正常运行时只有一个线程是在running其他线程都是sleeping。