开门见山
public class ScheduledThreadPoolExecutor
extends ThreadPoolExecutor
implements ScheduledExecutorService {
public ScheduledThreadPoolExecutor(int corePoolSize) {
//super调用父类的构造方法 即调用ThreadPoolExecutor的构造方法
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
}
public ScheduledFuture< ? > scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit) {
//参数检验,失败抛异常
if (command == null || unit == null)
throw new NullPointerException();
if (period <= 0)="" throw="" new="" illegalargumentexception();="" 接收一个runnable任务,延期执行时间,周期执行时间,并且将他们封装到一个scheduledfuturetask中="" scheduledfuturetask<="" void=""> sft =
new ScheduledFutureTask< Void>(command,
null,
triggerTime(initialDelay, unit),
unit.toNanos(period));
RunnableScheduledFuture< Void> t = decorateTask(command, sft);
sft.outerTask = t;
//任务存放队列,并判断是否需要创建线程
delayedExecute(t);
return t;
}
//接收入参 包装任务
ScheduledFutureTask(Runnable r, V result, long ns, long period) {
super(r, result);
this.time = ns;
this.period = period;
//sequenceNumber是ScheduledThreadPoolExecutor的一个成员变量:序列号,每次新建一个ScheduleFutureTask都会自增。
this.sequenceNumber = sequencer.getAndIncrement();
}
private void delayedExecute(RunnableScheduledFuture< ? > task) {
//如果线程池已经关闭,采用拒绝策略
if (isShutdown())
reject(task);
else {
//所有的任务都会先放到DelayedWorkQueue队列里,DelayedWorkQueue的add方法直接调用offer()方法
super.getQueue().add(task);
if (isShutdown() &&
!canRunInCurrentRunState(task.isPeriodic()) &&
remove(task))
task.cancel(false);
else
//然后再判断是否需要创建线程
ensurePrestart();
}
}
void ensurePrestart() {
int wc = workerCountOf(ctl.get());
if (wc < corePoolSize)
//addworker我们已经知道了,就是创建一个线程,执行线程的start()方法来调用Worker的runWorker()来获取任务并执行任务的run方法
//需要注意的是firstTask传的是null,这也就意味着新建的线程没有firstTask,都需要从队列中获取任务
addWorker(null, true);
//即使corePoolSize核心线程规定为0,也至少启动一个线程
else if (wc == 0)
addWorker(null, false);
//当前运行线程达到corePoolSize时,就不再创建线程
}
private class ScheduledFutureTask
extends FutureTask implements RunnableScheduledFuture {
public void run() {
boolean periodic = isPeriodic();
// 检查当前线程池状态是否需要取消
if (!canRunInCurrentRunState(periodic))
cancel(false);
// 如果不是周期性任务,直接调用父类FutureTask的run方法执行任务
else if (!periodic)
ScheduledFutureTask.super.run();
//否则,调用父类runAndReset方法执行任务,但是不设置结果,以便计算出下次执行的时间后,重复执行。
else if (ScheduledFutureTask.super.runAndReset()) {
//计算下次启动时间
setNextRunTime();
//里面有调用队列add方法来新增任务
reExecutePeriodic(outerTask);
}
}
---------
}
//队列新增任务
public boolean offer(Runnable x) {
if (x == null)
throw new NullPointerException();
RunnableScheduledFuture< ? > e = (RunnableScheduledFuture< ? >)x;
final ReentrantLock lock = this.lock;
lock.lock(); //加锁添加元素
try {
int i = size;
if (i >= queue.length)
grow(); //队列满扩容
size = i + 1;
if (i == 0) {
queue[0] = e;
setIndex(e, 0);
} else { //当队列中有元素的时候 调用sifUp升序方法
siftUp(i, e);
}
if (queue[0] == e) {
leader = null;
available.signal();//唤醒取元素的线程,告诉它工作队列中有元素可以取了
}
} finally {
lock.unlock();
}
return true;
}
//队列中取元素
public RunnableScheduledFuture< ?> take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
//取出第一个元素 ,放心第一个元素绝对是time最小的
RunnableScheduledFuture< ? > first = queue[0];
//连第一个元素都没取到,按理说不可能,第一次存任务可是主线程,然后主线程创建子线程
//这里是子线程获得cpu碎片后再来获取任务的
if (first == null)
available.await();
else {
//getdelay方法是把time减去当前时间,结果就是该任务离执行还有多长时间
long delay = first.getDelay(NANOSECONDS);
//如果执行时间恰好或者已经延期了,就把第一个任务扔给线程了
if (delay <= 0)=""
return finishPoll(first);
first = null; // don't retain ref while waiting
if (leader != null)
available.await();
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
//执行时间没到就睡眠相同时间
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && queue[0] != null)
available.signal();
lock.unlock();
}
}
//队列中取元素
private RunnableScheduledFuture< ? > finishPoll( RunnableScheduledFuture< ? > f) {
//firstTask扔给线程之前一些细节处理
int s = --size;
RunnableScheduledFuture< ? > x = queue[s];
queue[s] = null;
//最重要的是调用siftDown来选出下任firstTask(最紧急离执行时间越小的)
if (s != 0)
siftDown(0, x);
setIndex(f, -1);
//好了 这次取任务行动后续工作交接完毕,安心的走
return f;
}
在分析siftUp和siftDown之前先说明二叉树的定义,有助于我们理解代码
我们知道如果有一个二叉树的数组,抽象起来用树表示是这个样子: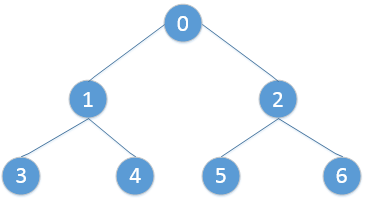
放在数组中后,是这个样子:
并且二叉树还有一个特性是:
任意结点的子节点的索引位置是其本身索引位置乘2后+1,比如,元素2的子节点是2*2+1=5
任意结点的父节点的索引位置是该结点的索引位置-1后除2并向下取整,比如6的子节点是(6-1)/2 = 2
这个特性对于查找父子结点来说非常的方便。
private void siftUp(int k, RunnableScheduledFuture< ?> key) {
while (k > 0) {
//查询父节点
int parent = (k - 1) >>> 1;
//取出父节点中的元素
RunnableScheduledFuture< ?> e = queue[parent];
//如果子节点比父节点大 退出while循环
if (key.compareTo(e) >= 0)
break;
//否则子节点time比父节点小 父节点该让位了 父节点下移到子节点位置
queue[k] = e;
setIndex(e, k);
//新任务顺利取代父节点,并把k赋值为父节点,再for循环
k = parent;
}
//经过while循环我们确保新任务key再根节点到key所在子节点那一条线上的顺序
queue[k] = key;
setIndex(key, k);
}
每次新增任务调用siftup确保了根节点到新任务所在节点那一条线上是逐渐变大的,横向上并没有什么比较和改变
private void siftDown(int k, RunnableScheduledFuture< ?> key) {
//k是传进来的根节点是0 key是队列中最后的一个元素
int half = size >>> 1;
while (k < half) {
//取出父节点的(第一次while循环 父节点是0)左子节点
int child = (k << 1) + 1;
RunnableScheduledFuture< ?> c = queue[child];
//取出右子节点
int right = child + 1;
//左子节点和右子节点选出一个最小的
if (right < size && c.compareTo(queue[right]) > 0)
c = queue[child = right];
if (key.compareTo(c) <= 0)
break;
//最小的子节点赋值给父节点
queue[k] = c;
setIndex(c, k);
//并把子节点作为下次while循环的父节点
k = child;
}
//好了 经过while循环
//一条从根节点到子节点的线路出来了,这条线路的所有子节点和他父节点的另一个子节点相比是小的,然后这条线路都要往上升一级,
//因为根节点要走了嘛,所有的孙子变儿子,儿子变老子,老子变太爷了,对于没有升级的那几条线路来说还有机会的,哥哥弟弟们没比的过,下次再有线程来取任务的话就可以和外甥们比了
queue[k] = key;
setIndex(key, k);
}
因为每次取任务仅仅需要一个最小的节点,也就没必要花费时间来把所有的节点从上到下从左到右依次来排序了。
这里有一个理解技巧就是因为存任务时已经确保所有父节点time都是小于它的子节点的,不然存任务的时候就会被子节点替换下来了。所以firstTask的位置肯定是queue[1]和queue[2]争取的,随便一个当上了firstTask,位置空缺都要由字节点来争取的,子节点的升级了,它的位置也空缺了,也要由子节点的子节点来争取,对于没有升级的节点来说,他们比输了位置没变,儿子们别想篡位(存任务的时候就确保了父节点都是优于子节点的)!
感谢http://ju.outofmemory.cn/entry/99456 博客的指点迷津