sqlserver单表数据超过2000w后,索引查询的效率开始下降。当数据过亿后,就开始有慢sql出现了。如何对这种体量的数据库进行优化,成为开发最头疼的事情。
分区
把一张表的数据分成N个区块,在逻辑上看最终只是一张表,但底层是由N个物理区块组成的。
常见的分区方式有:
- Range(范围,根据id大小分区,有热点问题,id越大代表越新,查询次数越多,id越小代表数据越陈旧,几乎无查询)
- Hash取模(哈希,对id进行取模运算,将数据均匀分布到事先设计好的分区中,后续如果模值变动,需要数据迁移)
- 按照时间拆分 (同range)
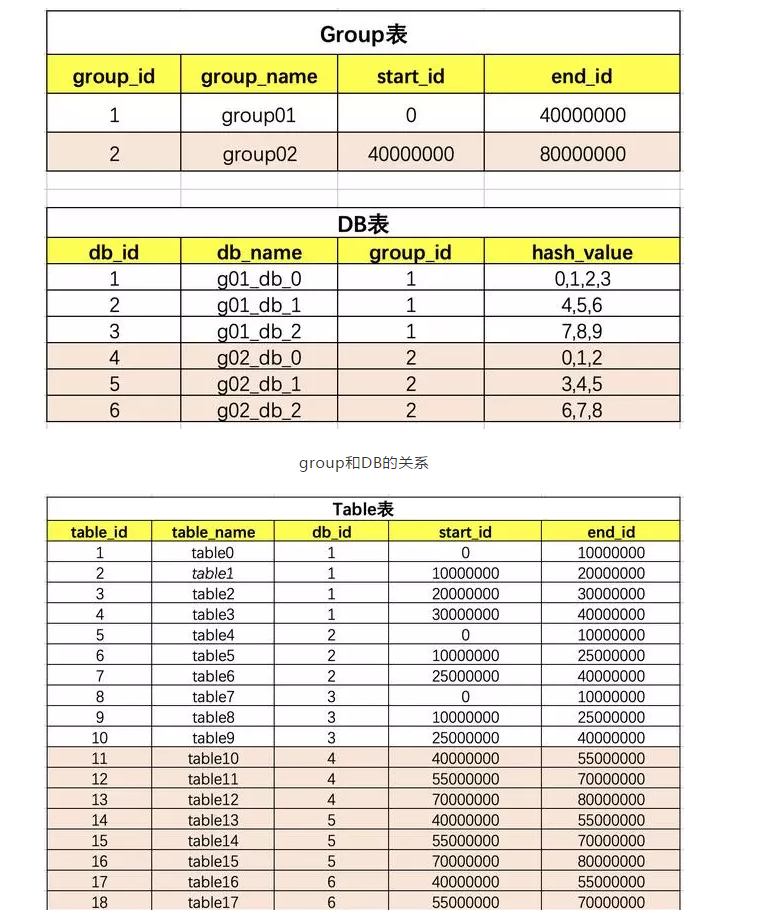
- Range+Hash取模 (分区+分库的实现形式,单表保存id和group的映射关系,再根据group内id取模运算,均匀落库到指定的db中,后续扩容直接新增一个group组即可)
按照时间拆分的一个完整示例
查询分区结果示例
|
|
Range+hash的架构图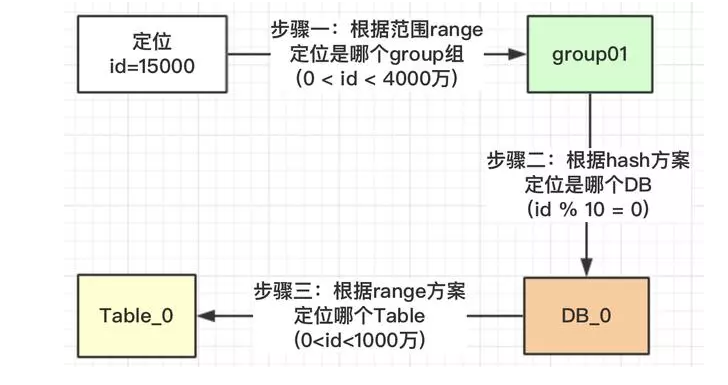
分表
是把一张表分成多个小表,适用如下场景: 单表的部分字段频繁的需要修改,可以将该类字段独立出来成一张表,实现单库的”读写分离”
分库
对于时效性不高的数据,可以通过读写分离缓解数据库压力,需要注意的是在业务分区上哪些业务是允许一定延迟的,以及数据同步问题
分片
在分布式存储系统中,数据需要分散存储在多台设备上,数据分片就是用来确定数据在多台存储设备上分布的技术。数据分片的目的是
- 分布均匀,每台设备上的数据量要尽可能详尽
- 负载均衡,每台设备上的请求量要尽可能相近
- 扩缩容时产生的数据迁移尽可能少