guavaCache的使用
ehcache的使用
redis的使用
缓存穿透
我们在项目中使用缓存通常先检查缓存中数据是否存在,如果存在则直接返回缓存内容,如果不存在就直接查询数据库,然后进行缓存并将查询结果返回。如果我们查询的某一数据在缓存中一直不存在,就会造成每一次请求都查询DB,这样缓存就失去了意义,在流量大时,可能DB就“挂掉”了,这就是缓存穿透。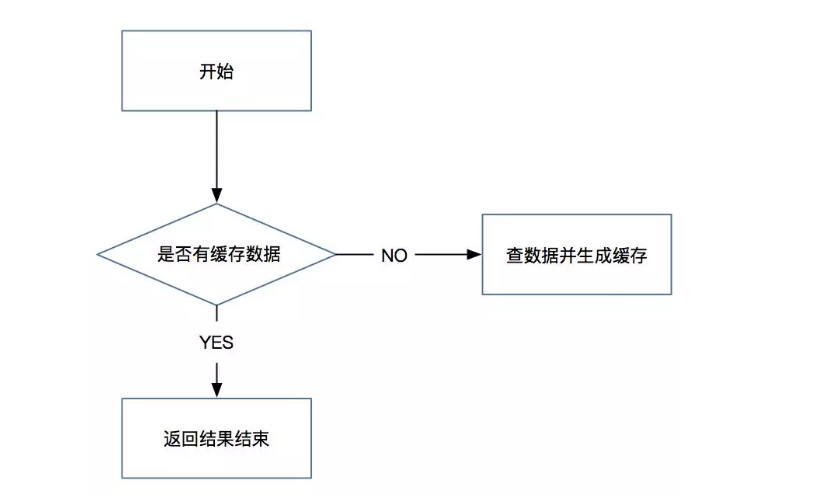
很多缓存穿透都是无意的,虽然线上发生概率小,但是如果真发生了就会造成服务宕机的局面。一般的解决方案是如果数据库查询不到结果,则默认返回一个预先设定的值。则过一个时间轮询点后,再次请求这个key,如果取到的值不再是NULL,则可以认为这时候key有值了,从而避免透传到数据库,把大量的类似请求挡在了缓存之中。
缓存并发
如果同一时间内,有大量相同的请求(比如黑客攻击),如果缓存中为null,那么所有的请求可能会穿过redis访问数据库,在流量大时,可能DB就“挂掉”了,这就是缓存并发。
- 每天凌晨定时任务将数据刷新到缓存中,后续请求数据只能从缓存中,不允许读取db。如果页面有新增或更新操作也需要同步缓存。
- 所有的请求使用分布式锁,每次穿过缓存后,加上锁、读取缓存数据(如果命中返回)、读取db、返回数据并同步缓存
- setNx(这种方法类似加锁)。
setNx: 客户端从缓存中根据key读取数据,如果读到了数据则流程结束,如果没有读到数据(可能会有多个并发都没有读到数据),则使用缓存系统中的setNX方法设置一个值(这种方法类似加锁),没有设置成功的请求则“sleep”一段时间,设置成功的请求则读取数据库获取值,如果获取到则更新缓存,流程结束,之前sleep的请求唤醒后直接从缓存中读取数据,此时流程结束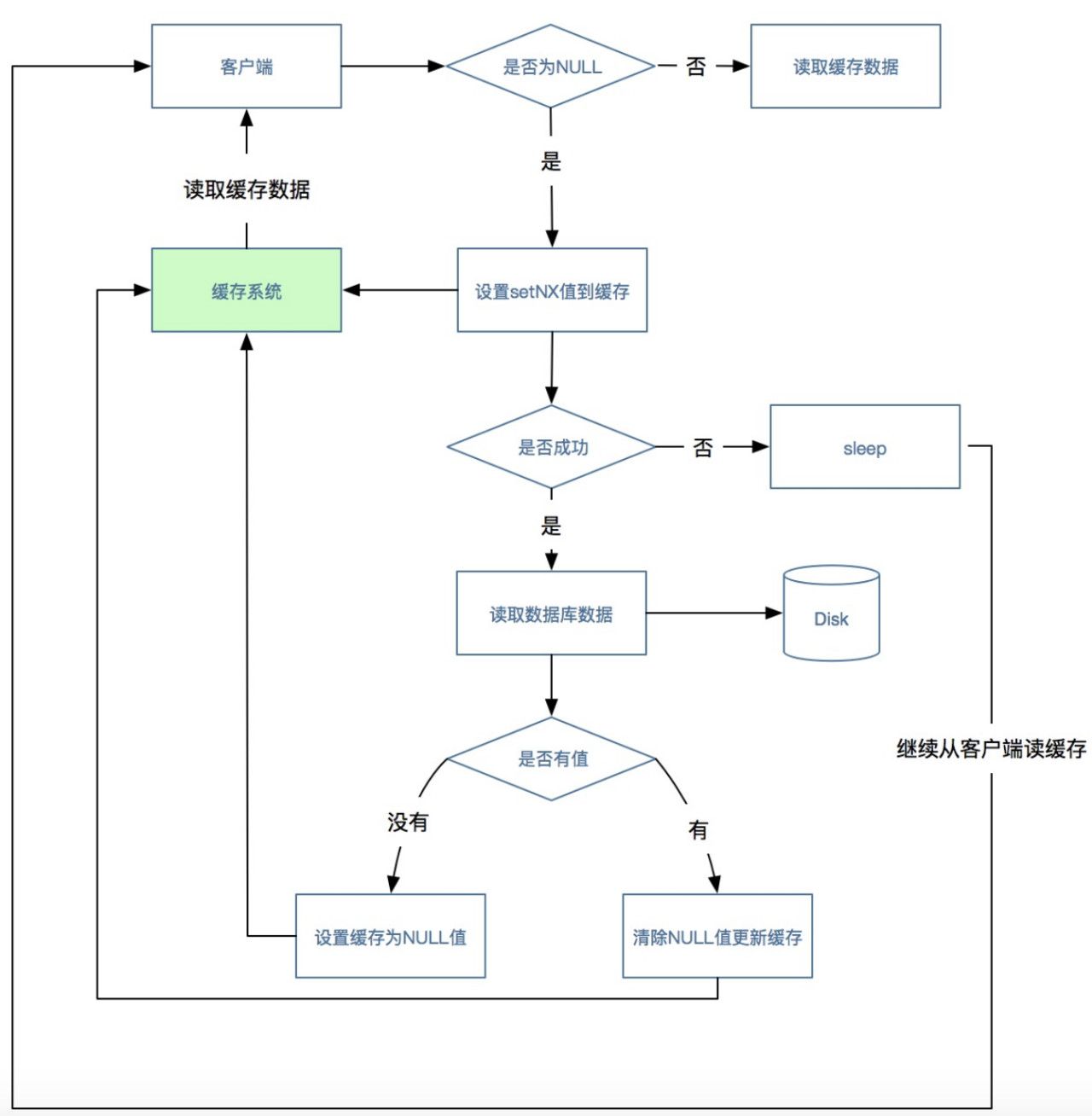
缓存过期导致惊群效应
如果很多缓存设置的过期时间是一样的,就会导致在一段时间内同时生成大量的缓存,然后在另外一段时间内又有大量的缓存失效,大量请求就直接穿透到数据库中,导致后端数据库的压力陡增,这就是“缓存过期导致的惊群效应”。比较合理的解决方案之一:为每个缓存的key设置的过期时间再加一个随机值,可以避免缓存同时失效。解决方案二:所有缓存设置过期时间为永久,有业务上的新增或者更新才去同步缓存。
最终一致性
最终一致性是指当后端的程序在更新数据库数据完成之后,同步更新缓存失败,后续利用补偿机制对缓存进行更新,以达到最终缓存的数据与数据库的数据是一致的状态。
- 基于MQ的缓存补偿方案。
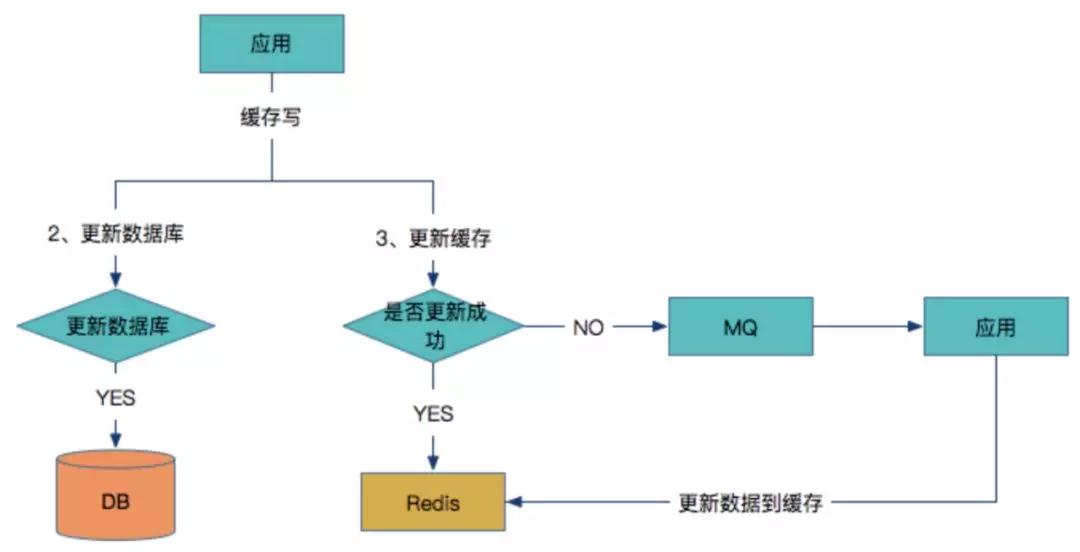
如果更新Redis失败,同时在将数据发到MQ之前应用重启了,那么MQ就没有需要更新的数据,如果Redis对所有数据没有设置过期时间,同时在读多写少的场景下,那么只能通过人工介入来更新缓存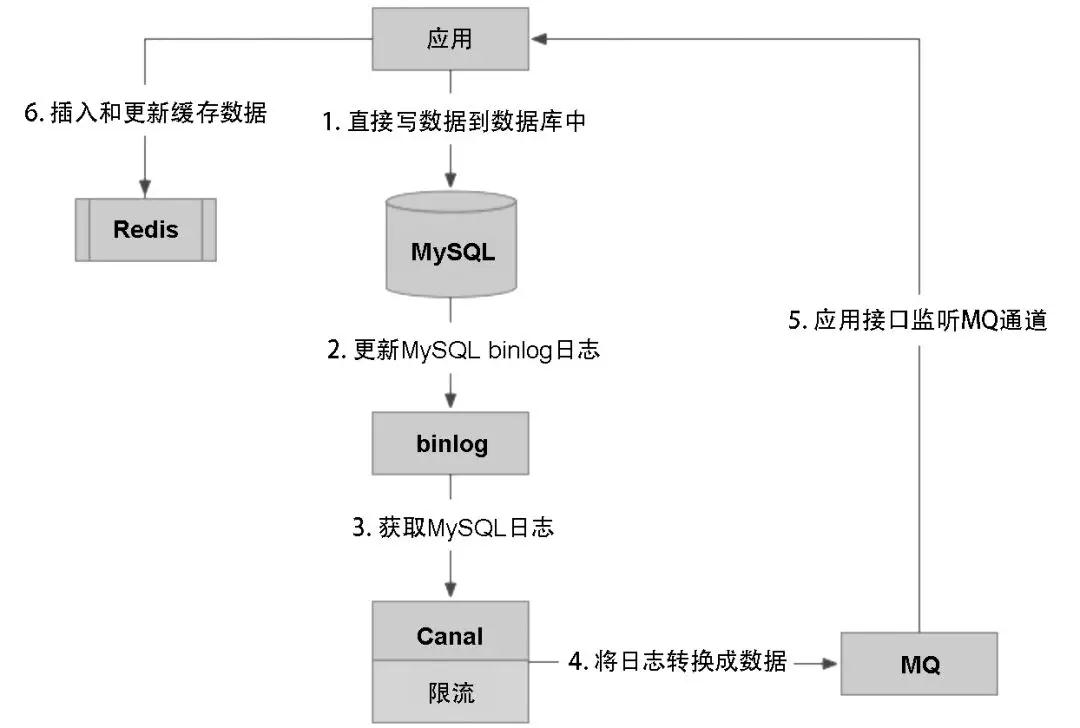
- 基于binlog的方式来实现统一缓存更新方案
这种方案的弊端是需要提前约定缓存的数据结构,如果使用者采用多种数据结构来存放数据,则方案无法做成通用的方式,同时极大地增加了方案的复杂度