多用户操作的数据问题
- 更新丢失:多个用户同时对一个数据资源进行更新,必定会产生被覆盖的数据,造成数据读写异常
- 不可重复读:如果一个用户在一个事务中多次读取一条数据,而另外一个用户则同时更新啦这条数据,造成第一个用户多次读取数据不一致
- 脏读:第一个事务读取第二个事务正在更新的数据表,如果第二个事务还没有更新完成,那么第一个事务读取的数据将是一半为更新过的,一半还没更新过的数据,这样的数据毫无意义
- 幻读:第一个事务读取一个结果集后,第二个事务,对这个结果集经行增删操作,然而第一个事务中再次对这个结果集进行查询时,数据发现丢失或新增
sql锁分类
为了解决多用户操作产生的数据问题,数据库系统引入了锁
- 共享锁(S):还可以叫他读锁。可以并发读取数据,但不能修改数据。也就是说当数据资源上存在共享锁的时候,所有的事务都不能对这个资源进行修改,直到数据读取完成,共享锁释放
- 排它锁(X):还可以叫他独占锁、写锁。就是如果你对数据资源进行增删改操作时,不允许其它任何事务操作这块资源,直到排它锁被释放,防止同时对同一资源进行多重操作。
- 更新锁(U):防止出现死锁的锁模式,两个事务对一个数据资源进行先读取在修改的情况下,使用共享锁和排它锁有时会出现死锁现象,而使用更新锁则可以避免死锁的出现。资源的更新锁一次只能分配给一个事务,如果需要对资源进行修改,更新锁会变成排他锁,否则变为共享锁。
- 意向锁:SQL Server需要在层次结构中的底层资源上(如行,列)获取共享锁,排它锁,更新锁。例如表级放置了意向共享锁,就表示事务要对表的页或行上使用共享锁。在表的某一行上上放置意向锁,可以防止其它事务获取其它不兼容的的锁。意向锁可以提高性能,因为数据引擎不需要检测资源的每一列每一行,就能判断是否可以获取到该资源的兼容锁。意向锁包括三种类型:意向共享锁(IS),意向排他锁(IX),意向排他共享锁(SIX)。
事务隔离级别
- Read Uncommited(RU):读未提交,一个事务可以读到另一个事务未提交的数据。最低的级别,存在脏读。
- read committed:这个级别是默认选项,不能脏读,不能读取事务正在处理没有提交的数据,但能修改,所以存在幻读
- repeatable read:不能读取事务正在处理的数据,也不能修改事务处理数据前的数据,可重复读,加入间隙锁,一定程度上避免了幻读的产生
- serializable:最高事务隔离级别,只能看到事务处理之前的数据
判断加锁的前置条件
- 当前系统的隔离级别是什么
- id列是不是主键
- id列如果不是主键,那么id列上有索引吗
- 如果存在索引是聚簇索引还是非聚簇索引呢
判断加锁示例
id列是主键,RC隔离级别
id是主键时,此SQL只需要在id=10这条记录上加X锁即可。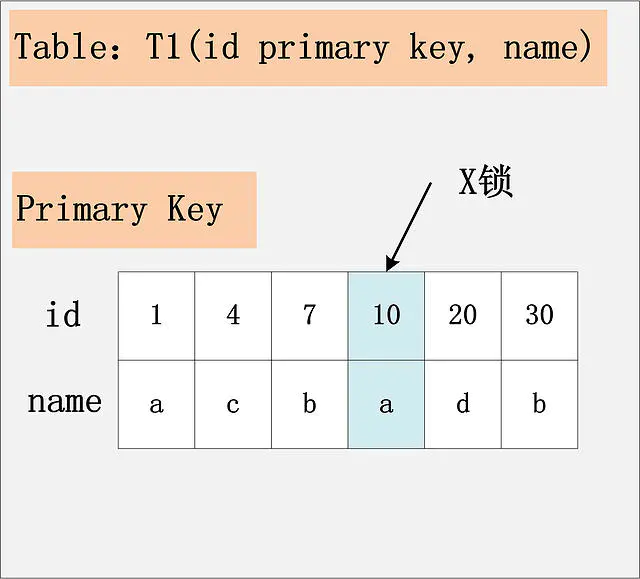
id列是二级唯一索引,RC隔离级别
若id列是unique列,其上有unique索引。那么SQL需要加两个X锁,一个对应于id unique索引上的id = 10的记录,另一把锁对应于聚簇索引上的[name=’d’,id=10]的记录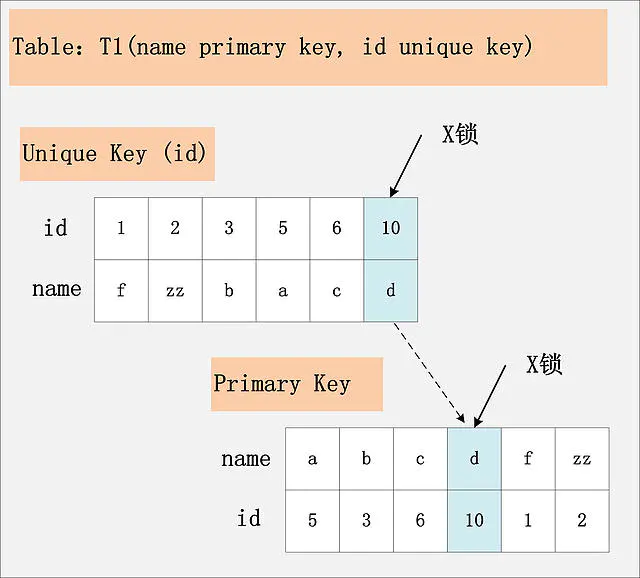
id列是二级非唯一索引,RC隔离级别
若id列上有非唯一索引,那么对应的所有满足SQL查询条件的记录,都会被加锁。同时,这些记录在主键索引上的记录,也会被加锁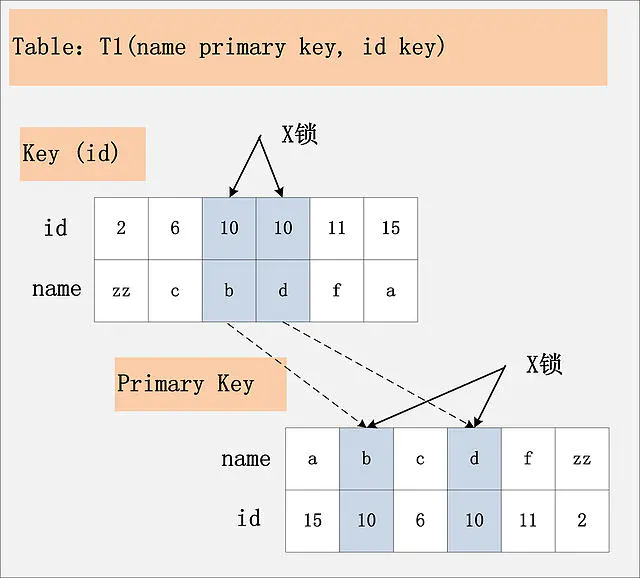
id列上没有索引,RC隔离级别
若id列上没有索引,SQL会走聚簇索引的全扫描进行过滤,由于过滤是由MySQL Server层面进行的。因此每条记录,无论是否满足条件,都会被加上X锁。但是,为了效率考量,MySQL做了优化,对于不满足条件的记录,会在判断后放锁,最终持有的,是满足条件的记录上的锁,但是不满足条件的记录上的加锁/放锁动作不会省略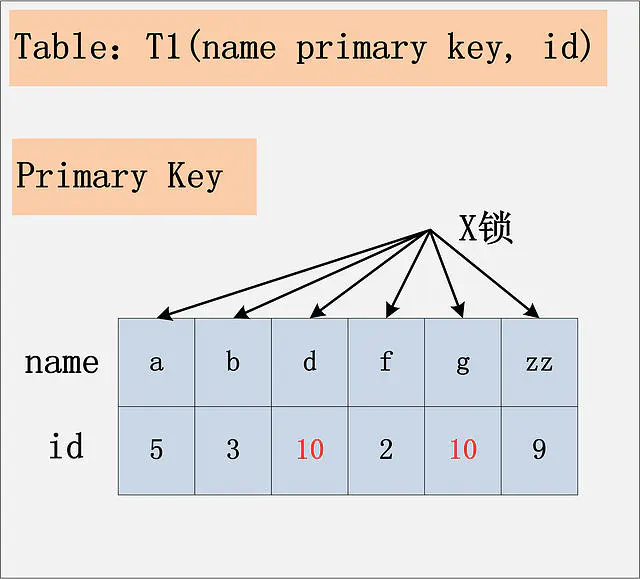
id列是主键,RR隔离级别
同RC
id列是二级唯一索引,RR隔离级别
同RC
id列是二级非唯一索引,RR隔离级别
Repeatable Read隔离级别下,id列上有一个非唯一索引,对应SQL:delete from t1 where id = 10; 首先,通过id索引定位到第一条满足查询条件的记录,加记录上的X锁,加GAP上的GAP锁,然后加主键聚簇索引上的记录X锁,然后返回;然后读取下一条,重复进行。直至进行到第一条不满足条件的记录[11,f],此时,不需要加记录X锁,但是仍旧需要加GAP锁,最后返回结束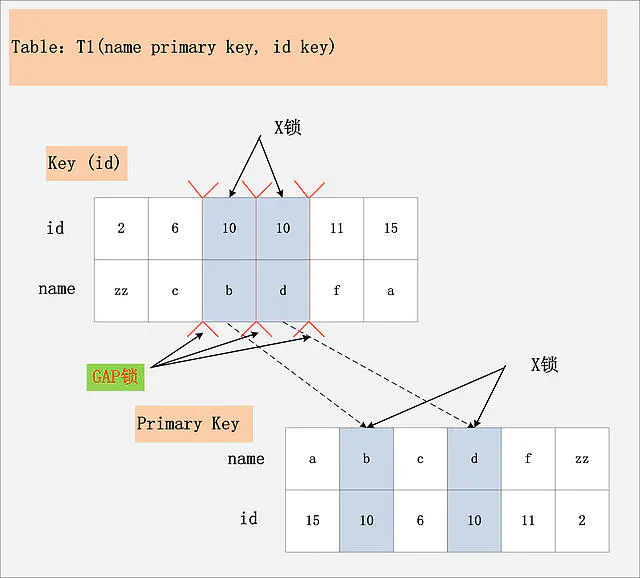
RR隔离级别,相对于RC隔离级别,不会出现幻读的关键,其实就是这个多出来的GAP锁。
考虑到B+树索引的有序性,满足条件的项一定是连续存放的。记录[6,c]之前,不会插入id=10的记录;[6,c]与[10,b]间可以插入[10, aa];[10,b]与[10,d]间,可以插入新的[10,bb],[10,c]等;[10,d]与[11,f]间可以插入满足条件的[10,e],[10,z]等;而[11,f]之后也不会插入满足条件的记录。因此,为了保证[6,c]与[10,b]间,[10,b]与[10,d]间,[10,d]与[11,f]不会插入新的满足条件的记录,MySQL选择了用GAP锁,将这三个GAP给锁起来。
而组合五,id是主键;组合六,id是unique键,都能够保证唯一性。一个等值查询,最多只能返回一条记录,而且新的相同取值的记录,一定不会在新插入进来,因此也就避免了GAP锁的使用。
在这种情况下,这个表上,除了不加锁的快照度,其他任何加锁的并发SQL,均不能执行,不能更新,不能删除,不能插入,全表被锁死。
id列上没有索引,RR隔离级别
在这种情况下,这个表上,除了不加锁的快照度,其他任何加锁的并发SQL,均不能执行,不能更新,不能删除,不能插入,全表被锁死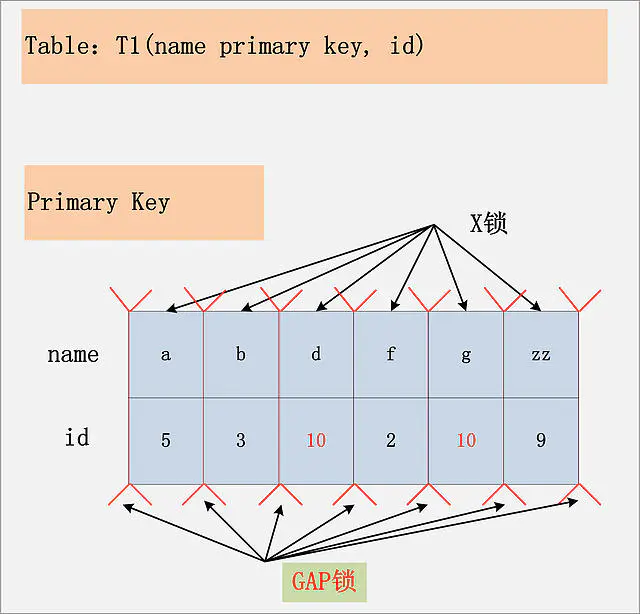
Serializable隔离级别
Serializable隔离级别,影响的是SQL1:select * from t1 where id = 10; 这条SQL,在RC,RR隔离级别下,都是快照读,不加锁。但是在Serializable隔离级别,SQL1会加读锁,也就是说快照读不复存在,MVCC并发控制降级为Lock-Based CC
一条复杂的sql

- Index key: pubtime > 1 and puptime < 20。此条件,用于确定SQL在idx_t1_pu索引上的查询范围。
- Index Filter: userid = ‘hdc’ 。此条件,可以在idx_t1_pu索引上进行过滤,但不属于Index Key。
- Table Filter: comment is not NULL。此条件,在idx_t1_pu索引上无法过滤,只能在聚簇索引上过滤。
在Repeatable Read隔离级别下,针对一个复杂的SQL,首先需要提取其where条件。Index Key确定的范围,需要加上GAP锁;Index Filter过滤条件,视MySQL版本是否支持ICP,若支持ICP,则不满足Index Filter的记录,不加X锁,否则需要X锁;Table Filter过滤条件,无论是否满足,都需要加X锁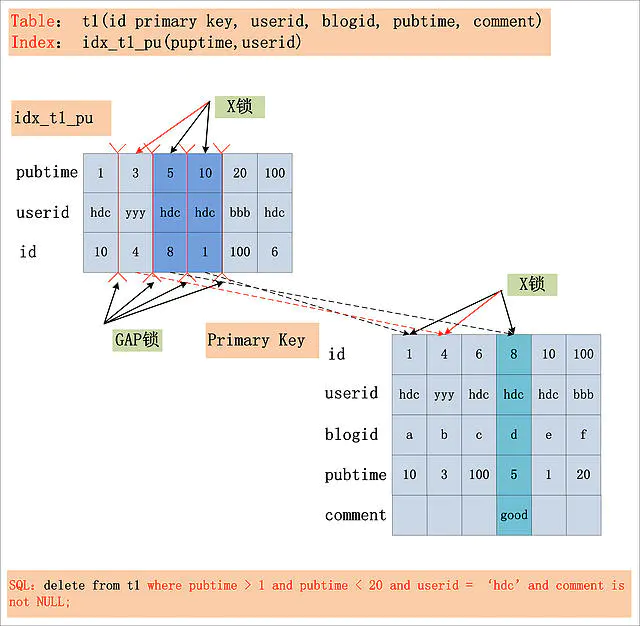
【相关文献】
https://www.jianshu.com/p/7c5dae9e40ea
https://www.cnblogs.com/knowledgesea/p/3714417.html
https://www.cnblogs.com/youngdeng/p/12857007.html