给定一条SQL,如何提取其中的where条件?where条件中的每个子条件,在SQL执行的过程中有分别起着什么样的作用?
关系型数据库中的数据组织
关系型数据库中,数据组织涉及到两个最基本的结构:表与索引。表中存储的是完整记录,一般有两种组织形式:堆表(所有的记录无序存储),或者是聚簇索引表(所有的记录,按照记录主键进行排序存储)。索引中存储的是完整记录的一个子集,用于加速记录的查询速度,索引的组织形式,一般均为B+树结构
|
|
t1表的存储结构如下图所示(只画出了idx_t1_bcd索引与t1表结构,没有包括t1表的主键索引):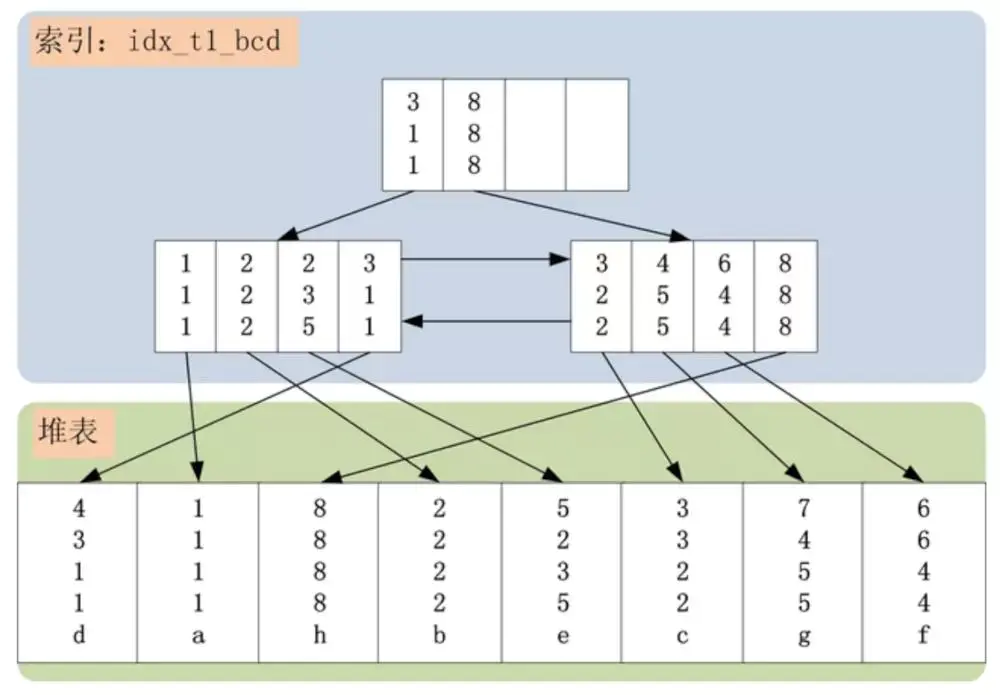
SQL的where条件提取
|
|
- 起始范围:记录[2,2,2]是第一个需要检查的索引项。索引起始查找范围由b >= 2,c > 1决定
- 终止范围:记录[8,8,8]是第一个不需要检查的记录,而之前的记录均需要判断。索引的终止查找范围由b < 8决定;
- 根据SQL,固定了索引的查询范围[(2,2,2),(8,8,8))之后,此索引范围中并不是每条记录都是满足where查询条件的。例如:(3,1,1)不满足c > 1的约束;(6,4,4)不满足d != 4的约束。而c,d列,均可在索引idx_t1_bcd中过滤掉不满足条件的索引记录的。因此,SQL中还可以使用c > 1 and d != 4条件进行索引记录的过滤
- e != ‘a’这个查询条件,无法在索引idx_t1_bcd上进行过滤,因为索引并未包含e列。e列只在堆表上存在,为了过滤此查询条件,必须将已经满足索引查询条件的记录回表,取出表中的e列,然后使用e列的查询条件e != ‘a’进行最终的过滤
所有SQL的where条件,均可归纳为3大类:Index Key (First Key & Last Key),Index Filter,Table Filter
Index Key
用于确定SQL查询在索引中的连续范围的查询条件,被称之为Index Key被拆分为Index First Key和Index Last Key,分别用于定位索引查找的起始,以及索引查询的终止条件
- Index First Key:
从索引的第一个键值开始,检查其在where条件中是否存在,若存在并且条件是=、>=,则将对应的条件加入Index First Key之中,继续读取索引的下一个键值,使用同样的提取规则;若存在并且条件是>,则将对应的条件加入Index First Key中,然后终止Index First Key的提取。
针对上面的SQL,应用这个提取规则,提取出来的Index First Key为(b >= 2, c > 1)。由于c的条件为 >,提取结束,不包括d - Index Last Key:
从索引的第一个键值开始,检查其在where条件中是否存在,若存在并且条件是=、<=,则将对应条件加入到Index Last Key中,继续提取索引的下一个键值,使用同样的提取规则;若存在并且条件是 < ,则将条件加入到Index Last Key中,同时终止提取;若不存在,同样终止 Index Last Key的提取。
针对上面的SQL,应用这个提取规则,提取出来的Index Last Key为(b < 8),由于是 < 符号,因此提取b之后结束
Index Filter
同样从索引列的第一列开始,检查其在where条件中是否存在:
1 若存在并且where条件仅为 =,则跳过第一列继续检查索引下一列,下一索引列采取与索引第一列同样的提取规则;
2 若where条件为 >=、>、<、<= 其中的几种,则跳过索引第一列,将其余where条件中索引相关列全部加入到Index Filter之中;
3 若索引第一列的where条件包含 =、>=、>、<、<= 之外的条件,则将此条件以及其余where条件中索引相关列全部加入到Index Filter之中;
4 若第一列不包含查询条件,则将所有索引相关条件均加入到Index Filter之中。
针对上面的用例SQL,索引第一列只包含 >=、< 两个条件,因此第一列可跳过,将余下的c、d两列加入到Index Filter中。因此获得的Index Filter为 c > 1 and d != 4
Table Filter
Table Filter是最简单,也是提取最为方便的。提取规则:所有不属于索引列的查询条件,均归为Table Filter之中。
针对上面的用例SQL,Table Filter就为 e != ‘a’